
In part one of this series, I laid out a pretty grim reality for many organizations seeking to gain insight from data science. For this post, I will spend more time talking about the exciting possibilities that can be accomplished with data science rather than the pitfalls.
Why Data Science?
People who no longer want to bother with data science will often ask me: Why not just use data visualization to solve all our problems? My answer would be: Humans are limited in their ability to see and, in effect, our dashboards are limited as well. We cannot see anything greater than three dimensions. So, how could we expect to find natural groupings in our data that is almost always greater than three dimensions?
Would a marketing company be able to profile potential customers based on three data points? Statistics, machine learning algorithms and AI all seek to either remove human bias, automate impossible tasks for human analysts or discover relationships that only decades of Excel scrolling could discover in fractions of the time.
Anticipating the future or discovering unique trends in your customers’ behavior are now realistic outcomes from your data. Furthermore, data science allows us to take those insights and turn them into actions. The ROI of this intelligent automation should have more actions that happen at the speed of your business.
Laboratories Are the Answer
As I mentioned in my previous post, one of the common pitfalls of data science management is to treat it like a software development project. This fails mainly because of how it handles uncertainty, allows for iterations and accounts for value.
Project management is still necessary to keep teams accountable. However, it is time to stop treating data science like an IT function and more like a laboratory. Laboratories allow for a change in mindset, management and, greatest of all, create a more collaborative environment.
The Laboratory Team
It’s no secret that collaboration yields better products. Diversity on a data science team is a must. There are simply too many areas in data science to have a hands-on experience or an in-depth understanding. For example, instead of finding one unicorn, it’s much more productive to find three or four people who, between them all, each know more than one unicorn. Take the following chart from “Doing Data Science” as an example:
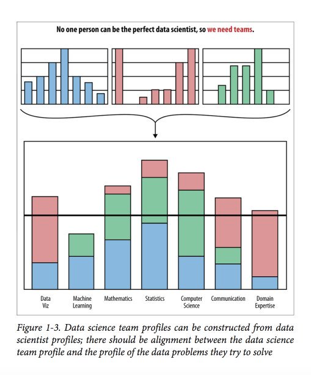
Above: Visual representation of a potential data science team.
The Laboratory Rules
“There ain’t no rules around here. We’re trying to accomplish something.” – Thomas Edison, probably.
Jokes aside, this is a very important point. There is a lot to learn and we need to create a space for that to happen. Whether you prefer agile, waterfall or whatever the next big thing is, the focus needs to be on allowing the right allocation of skills and, most importantly, tinkering. Tinkering allows members across multiple projects to poke and prod one another’s ideas.
Tinkering is an attitude that says, “Before I settle on this being the solution, let’s spend some time with people across project teams to make sure this is the best we can come up with.” Creating an environment that rewards experimentation and allows for quick recovery from failure can be hard in most corporate cultures that seek to prevent any failure at all.
Remember, your data scientists aren’t practicing medicine. They are intelligent creatives that need room to do their job well. Only put the necessary rules and procedures in place to avoid major disasters (like sensitive data being lost or stolen), and follow all moral, ethical and legal requirements.
The Laboratory Environment
From a technical perspective, laboratories should be allowed to constantly add and take away from a data environment in order to focus on better solutions. This means that not every laboratory will have the same tool stack. Generally, here are some key rules of thumb:
- The environment should be able to access all available data. Maybe this does not need to happen right away, but if your company has data stored in Hadoop or on a file share, the environment should be flexible enough to accommodate.
- The environment should be able to support the programming language(s) of choice. A Python library for machine learning may often provide better functionality than an R library and vice versa. A laboratory team should be able to interchange programming languages and install the libraries they need to get their jobs done.
- The environment should seek to maximize time spent on “science,” not on data cleaning. Tools that help accelerate data cleaning and munging should be deployed so data scientists can spend less time on cleaning data and more time on model building or statistical analysis.
- The environment should scale. This often means the cloud must be flexible enough for servers to spin up or down based on computational needs.
- The environment should be collaborative. Version control tools, communication tools and shared servers should be used to help decrease multiple versions of the truth and overlapping work.
Fitting the Laboratory into Your Existing Systems
As an example, here is a client recommended drawing on how best to fit data science into existing Tableau reporting infrastructure:

Above: An ideal data science flow chart.
In the image above, the laboratory is like a helicopter hovering over the environment. It can deploy Tableau reports to business users and interact with reporting and source data.
Dataiku
You can absolutely create an environment like this with some good, old-fashioned IT work and open source technologies. However, if you want to streamline things a bit, you’ll need a different tool to utilize source data. Dataiku is a tool we use internally that provides amazing orchestration and a collaborative layer to the laboratory.
Dataiku (pronounced like “haiku,” but with data at the beginning) is focused on making collaborative data science easy and fast. For business users, it incorporates drag-and-drop tools for data cleaning and shaping.
For data scientists, it gives you the flexibility to code whatever you want in common languages your team will know (Python, R, SQL and Scala) along with pre-built modules to do everything from profiling to predictive modeling. For IT, it allows models to be surfaced via APIs, flows to be automated and monitored, and even the creation of web apps for business-friendly tools without the need to build yet another server environment.
This tool is truly designed around the data science process with flexibility in mind. It can easily sit on top of your data environment, from typical relational databases to a Hadoop environment that runs Spark or H2O.
I am a huge fan of open source, so it takes a lot to get me excited about an enterprise tool. But I genuinely love what this company is doing. Look out for some future blogs that dig further into Dataiku’s functionality and InterWorks’ partnership with them.
Final Thoughts
My vision for laboratory environments is not that different from what others espouse. Ultimately, in order to overcome the pitfalls of data science, focus must be placed on business value, collaboration within data science teams and business users, and giving data science teams a successful environment.
The less time spent fighting red tape and poor environments, the more time data scientists have to focus on solutions and communication, which yields real value for any organization.